
The course is organized into progressive modules that build from foundational programming concepts to practical data science applications. It was designed in 2022, so most of the content was not AI generated. Only Spanish is supported.
It is designed to be read in a web browser, but all content is written as Jupyter Notebooks that you can open in Google Colab and run interactively. If you spot a mistake or want to contribute, feel free to open a PR or an issue.

Course Structure
- Python basics — syntax, data structures, control flow, functions, and OOP
- Scientific Computing with NumPy — array manipulation, indexing, and vectorized operations
- Data Visualization with Matplotlib — charts and visualizations for data analysis
- Data Analysis with Pandas — DataFrames, aggregation, and dataset merging
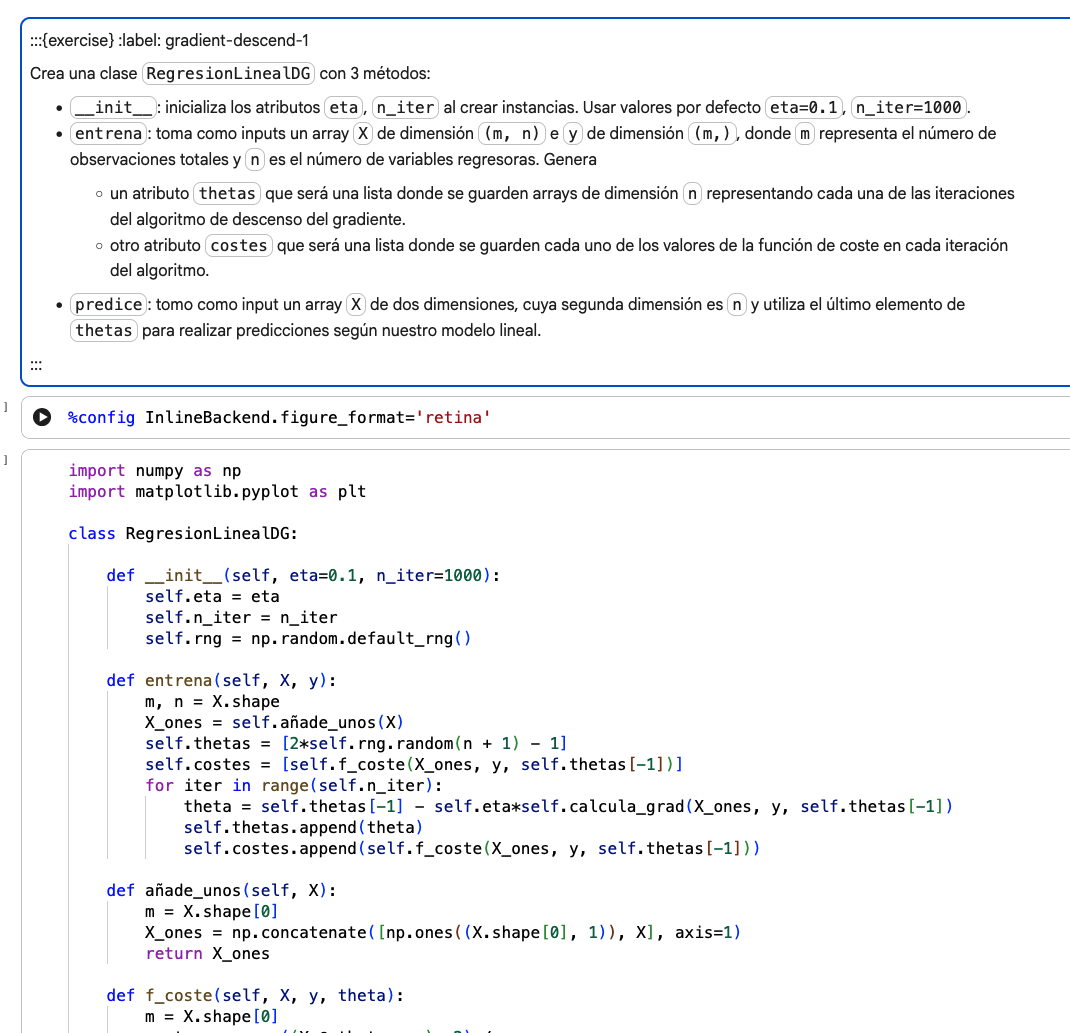
- Practical Case Studies — gradient descent, linear programming, portfolio optimization, regression, EDA, and binary classification
- Project Management — project structure and interactive dashboards with Dash
Interactive Learning
Each notebook contains executable code cells alongside markdown explanations. Exercises are embedded throughout the materials with collapsible solutions, allowing students to practice independently before checking their work.
Course Materials
All content is open source and available on GitHub. The course website is built with Jupyter Book, providing a clean reading experience with direct links to run notebooks in Google Colab.
Remember
>>> import thisBeautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren’t special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one— and preferably only one —obvious way to do it. Although that way may not be obvious at first unless you’re Dutch. Now is better than never. Although never is often better than right now. If the implementation is hard to explain, it’s a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea — let’s do more of those!
— The Zen of Python, by Tim Peters
References
The course draws from established Python and data science literature including:
- Python Distilled by David Beazley
- Python for Data Analysis by Wes McKinney
- Effective Pandas by Matt Harrison
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow by Aurelien Geron